I have been using Wicket for about one and a half year (and followed it about a year longer), and only recently I realized the tremendous flexibility of Wicket. The core developers keep introducing major features by replacing large and small parts of the core, without changing much of the existing programming interface. It doesn't stop there though. Any good developer can do the same with relatively little effort. On occasion I replaced important parts of the core myself, just because I wanted it a little bit different.
Upcoming release 1.4 is all about introducing the long awaited generic models. But the
release notes of Wicket 1.4-m1 contain another little gem. Created by non-core developer John Ray: child components within a wicket:message element. But before I explain what that means, lets first look at your internationalization options in Wicket.
This article requires you to have a very basic grasp of Wicket (what the application class is, how wicket:id is used, and simple components like Panel and Label). A bit of knowledge on Java properties helps as well.
Simple texts: wicket:message element, and wicket:message attribute
A simple web page easily contains dozens of texts that need i18n. It would be cumbersome to have to put a wicket:id on all of these, and then add a Label to each. Instead you can use the
wicket:message element in the HTML file directly. For example in MyPanel.html:
<wicket:message key="helloworld">Hello</wicket:message>
The key (
helloworld) is used to lookup the message in the property files. The default text (
Hello) is used when the message could not be found.
The property files are (MyPanel.properties):
helloworld: Hello world
And for Dutch(MyPanel_nl.properties):
helloworld: Hallo wereld
The ouput with an English locale:
Hello world
You can do the same for HTML attributes. For example:
<input type="submit" value="Default text"
wicket:message="value:helloworld"/>
Would result in:
<input type="submit" value="Hello world"/>
If there are multiple attributes to translate, add them prepended with a comma:
<input type="submit" value="Default text"
wicket:message="value:helloworld,title:hellotitle"/>
Wicket's locale selection
As usual in Java i18n systems, messages are looked up by locale. The locale is automatically extracted from the HTTP request, but can also be explicitly set with
getSession().setLocale(Locale.US).
If you need to override the locale for a specific component, override
getLocale() on that component and it will be used by that component and its children.
If a client does not provide a preferred Locale, Java's default Locale is used. See
Locale.getDefault() and
Locale.setDefault(Locale)) for more information.
Finding the message
Another extremely powerful concept is how the message is looked up in the property files. Normally a properties file with the same name as the current component is used. E.g. if you are working within the component SummaryPanel, the message is looked up in the file
SummaryPanel_nl_NL.properties (for Dutch, Netherlands locale). If that fails (either because the file does not exist, or because it does not contain the message), file
SummaryPanel_nl.properties, and then
SummaryPanel.properties are investigated. This is all just like Java's resource bundles work. But of course Wicket goes further. If the message is still not found, the property files of the
parent class are investigated, and again, and again, all the way up to
java.lang.Object. For each class all locale variants are searched for.
Components are reusable, but in order to make it really reusable you should be able to override the messages depending on where the component is used. This is facilitated by first looking up the message (following the algorithm above) for every parent in the
component hierarchy (aka page hierarchy). Every component can override the messages of its child components, so the search starts at the page's properties and then trickles down to the component that uses it (yes, its top-down). In order to make overrides specific to a certain child component, you can prefix the message key with the component id of the child. See
ComponentStringResourceLoader for more details.
If no message was found in the page hierarchy, another search starts which will look at your application class and its super classes. So Wicket first looks at
MyApplication.properties (provided
MyApplication is the name of your application) and then up the class hierarchy, passing
org.apache.wicket.Application, up to
java.lang.Object. This is how Wicket provides its many default i18n texts.
This might sound complicated, but in practice you simply have one properties file per page and some more for components that are reused over multiple pages. For smaller applications you can even put everything in one properties file. These rules work so well that you just do what you think is correct and it almost always just is.
One note on the location of the properties files: like HTML files, they must be in the same package (and same classloader) as the component they are associated with. In practice they live next to each other in the same directory.
If you want Wicket to get its resources from somewhere else (e.g. from a database), you can implement the interface org.apache.wicket.resource.loader.IStringResourceLoader and configure this in the
init() method of your application class.
References:
ExtensionResourceNameIterator,
ComponentStringResourceLoader, and for real control freaks the new
PackageStringResourceLoader.
Reloading and caching
When Wicket is started in development mode, changed properties files are detected and reloaded. To properly make use of this feature from an IDE, you should run Wicket directly from the compiled sources, for example with the
Start file, included in every
QuickStart. In Eclipse you just save the properties file, in IntelliJ you must do a make (Ctrl-F9) before changes are picked up.
In production mode, resolved properties are heavily cached for performance. (Same applies to html files.)
Putting dynamic values in the messages
As soon as you need to add values to the messages, you also need to add some Java code. The java code provides the vales, but the rest of the text still comes from the properties file. One of the nice things here is how Wicket leverages java bean properties.
Here is a complete example. Not many frameworks make this so easy!
MyPanel.properties:
summ: You, and ${otherCount} others, reviewed '${title}' \
and rated it ${rate}.
MyPanel.html:
<span wicket:id="summary">Text that will be replaced.</span>
MyPanel.java:
// Summary has getters for otherCount, title, etc.
Summary summary = ...;
add(new Label("summary", new StringResourceModel(
"summ", this, new Model(summary))));
Resulting in something like:
<span>You, and 5 others, reviewed 'Wicket in Action'
and rated it excellent.</span>
Property based message key
It goes further: do you know a framework that can do this?
MyPanel.properties:
summ.short: Thanks!
summ.long: You, and ${otherCount} others, reviewed '${title}' \
and rated it ${rate}. Thanks!
MyPanel.html:
<span wicket:id="summary">Text that will be replaced.</span>
MyPanel.java:
// summary.getMsgPrefs().getStyle() returns "short" or "long"
add(new Label("summary", new StringResourceModel(
"summ.${msgPrefs.style}", this, new Model(summary))));
And more!
The Java property syntax is also still available (e.g. like
{0,Date},
{2,number,###.##} etc.)? You can find all forms in the
javadocs of StringResourceModel.
The trouble with property files
Now this is all nice, but there is one problem you will frequently encountered while using string resources. In this problem you have a sentence that contains one or more dynamically constructed parts (for example some links). The order of these dynamic parts is potentially different for each locale. In the previous example, we may want to link to an information page on the title, and on the word 'others' open a modal window with a list of people.
If you try this with Wicket 1.3 (or any other Java framework I know of that uses resource bundles) you'll find that there is actually no pure way to do this. I know of 3 workarounds, but neither is very attractive. Lets review them. The first way is to split the texts before, after and between the dynamic components. This works good enough, but varying the order of the components is not possible unless you so something clever on the Java side, or have multiple HTML files. The latter is also workaround number 2: for each locale use a separate HTML file with the translation directly included (note: Wicket uses the same rules to lookup HTML files as it does for property files, e.g. MyPanel_nl.html just works like you expect it to). However, having more then one HTML file per component often leads to maintenance horror as changes must be synchronized over many files. The third workaround is to add placeholders to the message text that later are replaced by some HTML. That HTML is either hand written (in which case you may wonder why you started with Wicket at all), or you need to do some serious Wicket hacking to get components to render to a StringBuffer.
Now lets do this with Wicket 1.4-m1:
MyPanel.properties:
summ: You, and ${othersLink}, reviewed ${titleLink} \
and rated it ${rate}.
others: ${otherCount} others
MyPanel.html:
<wicket:message key="summ">Text that will be replaced.
<span wicket:id="rate">rate</span>
<a href="#" wicket:id="titleLink">
<span wicket:id="titleLabel">label</span></a>
<a href="#" wicket:id="othersLink">
<span wicket:id="othersLabel">label<</span></a>
</wicket:message>
MyPanel.java:
// Note, we directly add the embedded components
// rate, othersLink and titleLink
add(new Label("rate", new PropertyModel(summary, "rate")));
Link othLink = new Link("othersLink") { .... }
add(othLink);
othLink.add(new Label("othersLabel", new StringResourceModel(
"others", this, new Model(summary))));
ExternalLink titleLink = new ExternalLink(
"titleLink", summary.getTitleUrl());
add(titleLink);
titleLink.add(new Label("titleLabel",
new PropertyModel(summary, "title")));
The html file contains a wicket:message element with some embedded components. All text within the element is removed and replaced by the text from the properties file. Labels like
${othersLink} are replaced by the rendered component of the same wicket:id. That component must be embedded in the wicket:message element. Note that the order of the components is irrellevant. Also note that you will not see any reference to the wicket:message element in the java code.
If you want runnable code you can download the
complete example code (a Maven 2 project based on
Wicket's QuickStart). See below for instructions.
Getting string resources from code
Despite all of the above, there always remain some cases in which you need direct access to the messages. Luckily Wicket provides access through the
Localizer. You can get the localizer from any component with
getLocalizer().
Again, see the
complete example code for an example.
Encoding troubles
Fairly unknown to beginning programmers is that you are only allowed to use ISO-8859-1 encoding in java properties files. If you live in Europe this is a fairly annoying as many languages have characters that are not known to ISO-8859-1 (for example the euro symbol €). The simple workaround is escaping:
cree\u00EBr instead of
creeër. (I always use
this site to look up the ISO codepoint.)
But imagine you are making a site in Thai! Luckily Wicket can also read XML property files. Here is a fragment of the Thai properties that comes with Wicket:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<entry key="Required">ข้อมูลใน ${label} เป็นที่ต้องการ.</entry>
</properties>
Nice!
Sample code
To test the code in this article I created a
small test application. Unzip it, and run
mvn jetty:run to start it. When it is started access it on
http://localhost:8080/i18ntest.
Changing resource settings
Finally, if you need more power, you can change all of Wicket's settings in the
init() method of your application. Call
getResourceSettings() to get a
IResourceSettings instance. Let look at some of the options.
ThrowExceptionOnMissingResource: this will make Wicket throw an exception when a resource is missing. At first this may seem a convenient way to test that you listed all messages in a properties file. However, many standard Wicket components use defaults as fall back, so this option is mostly useless. Alternatively, watch for warnings in the log.
UseDefaultOnMissingResource: this will make Wicket use the default value (e.g. the text within the wicket:message element) when the resource is not found in a properties file. Setting this to true (the default) may hide errors for a long time, but setting this false will make your site not work if you made an error. Choose carefully.
There are many more options that allow you to change what, when and how properties are loaded. I have never found a use for these, but they are there if you need them.
Conclusion
As you have seen in this article, Wicket provides simple ways to do everything around internationalization, and some more less simple ways to completely customize this for the rare case you need it. Furthermore, the new Wicket 1.4 release will make it a lot better with support for componenta embedded in a wicket:message element. You can download the
example to see everything in action.
Update 20080526: Incorperated the comment from Stefan Fußenegger on what happens if the user gives no preferred locale.
Update 20080527: Scott Swank put this article on the
Wicket Wiki. Feel free to edit it there!
Update 20091203: Corrected text after Satish_j pointed out that I made a glaring mistake in the order messages are looked up in the page hierarchy.
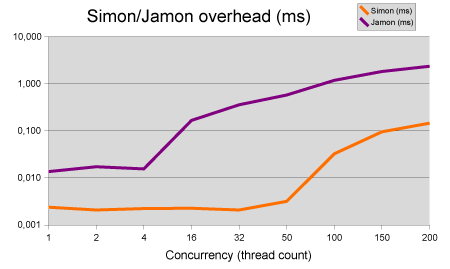 Simon's performance is pretty good! The overhead in my test application doesn't come anywhere near the millisecond range even in highly concurrent situations. Jamon is not so bad either, even though its 5 to 200 times slower, depending on thread contention. With 5 monitors in a request, the overhead per request slowly grows to 0.7 ms for Simon, and quickly grows to 12ms for Jamon.
Note: the test application does nothing else but getting monitors and doing measurements. So the right side of the chart is unrealistic for most environments.
Improving the performance
Simon's performance is pretty good! The overhead in my test application doesn't come anywhere near the millisecond range even in highly concurrent situations. Jamon is not so bad either, even though its 5 to 200 times slower, depending on thread contention. With 5 monitors in a request, the overhead per request slowly grows to 0.7 ms for Simon, and quickly grows to 12ms for Jamon.
Note: the test application does nothing else but getting monitors and doing measurements. So the right side of the chart is unrealistic for most environments.
Improving the performance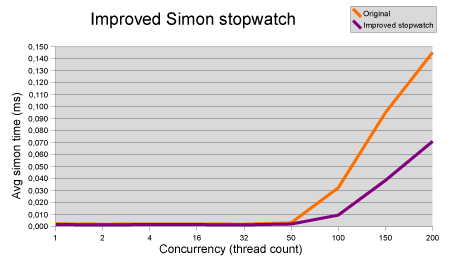 Not bad! Although the results are quite dramatic for the higher thread counts, it still shaves off 20% in situations with less contention.
Recommendation: remove the thread local from StopwatchImpl and change the API as described above.
Replace synchronized HashMap with a ConcurrentHashMap in EnabledManager
Not bad! Although the results are quite dramatic for the higher thread counts, it still shaves off 20% in situations with less contention.
Recommendation: remove the thread local from StopwatchImpl and change the API as described above.
Replace synchronized HashMap with a ConcurrentHashMap in EnabledManager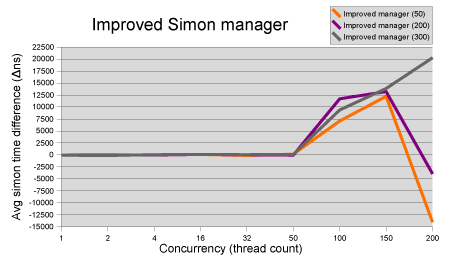 To my big surprise there is no measurable difference with modest contention. During high contention there is a reasonable positive effect that is suddenly converted to a negative effect for very high contention. Only when the currency level is set very high, does the effect stay positive.
Recommendation: don't change the manager.
Conclusions
Although Simon is only young, it is off with a good start. Its clearly faster then Jamon and also on the documentation front Simon wins. Jamon has much more features so it is still a valid choice. When the recommendations in this article are followed, Simon could be better still.
Discussion
To my big surprise there is no measurable difference with modest contention. During high contention there is a reasonable positive effect that is suddenly converted to a negative effect for very high contention. Only when the currency level is set very high, does the effect stay positive.
Recommendation: don't change the manager.
Conclusions
Although Simon is only young, it is off with a good start. Its clearly faster then Jamon and also on the documentation front Simon wins. Jamon has much more features so it is still a valid choice. When the recommendations in this article are followed, Simon could be better still.
Discussion{kind=link}